LPC810でもMMLでスーパーマリオを演奏させたい!
先日A tiny MML parserを使ったスーパーマリオ演奏アプリケーションを公開しました。
折角なので眠っているLPC810への移植を試みたところ、4KBのフラッシュ・ロムに収まらない事がわかりました。実装したスーパーマリオのMMLを眺めると繰り返し処理をべた書きしています。MMLの処理を削る事は有り得ないので、安直に曲データを圧縮する事を考えました。A tiny MML parserに繰り返し処理を追加する事で曲データを圧縮を可能にし、LPC810でもスーパーマリオを演奏出来るようにしようと考えたわけです。
そんなにスーパーマリオに拘っているわけではないのですが、8ビットのマイコンにやらせていた事を32ビットのマイコンに移植して「残念!」みたいな結果になるのが嫌だったわけです。それがたとえフラッシュ・ロムの容量が原因だったとしても!(いや、それは無理・・・なんですけど)
繰り返し処理の仕様を考える
ひとくちにMMLと言っても様々な仕様、様々な実装が存在します。
A tiny MML parserに追加する繰り返し処理の仕様を以下のように定めました。
- []の記号を用いて繰り返し処理の区間を定義するものとする。
- 繰り返し処理の区間はネストさせる事ができるものとする。
- 繰り返し処理の区間は二回繰り返し処理されるものとする。
一見簡単そうに見えます。
乱暴なプログラマの場合、いきなり実装に入ってしまうかもしれません。
ちょっと考えて「出来るんじゃね?」と思う訳ですが、この記事では「簡単そうに見える処理が実際もそうなのか?」という視点でも見てみたいと思います。
最初にテストデータを定義する
A tiny MML parserに繰り返し処理を追加するにあたって、最初にテストデータを定義しました。このテストデータを新しいバージョンのA tiny MML parserに与えて、期待する結果が得られれば新たに加えられた処理は正しいという理路整然としたアプローチです。
- [CDE]
- [CDE[FGA]]
- [[CDE]FGA]
- [[]]
- [C[D]E]
- [CD[EF]GA]
上記のテストデータは正常系のテストデータです。異常系は以下のようにしました。
- [[[[[[[[[[[[[[[[[[[[
- ]]]]]]]]]]]]]]]]]]]]
- [ ]]
- [[ ]
- ][
このようにちょっと単純すぎるテストデータですが、そもそもこの程度のテストデータを正しく処理出来ないとしたら論外です。そういう意味でも正常系と異常系のテストデータを簡単なもので良いから両方用意しておくというのは重要です。
安直な設計でどうなるのか考えてみる
それではここで、めちゃくちゃ安直に設計無しで実装に取りかかった場合、どのようになるのかシミュレーションしてみましょう。
新人A君の場合
新人A君は、学生時代にマイコンでプログラミングを楽しんでいた意欲的な新人です。
与えられた仕様に対して直感で「これは位置を記憶する変数とループ状態を保持するフラグがあれば解決出来る!」と意気込み、早速プログラミングに取りかかる事にしました。
新人A君は、とりあえず実装しながら動作を確認し、ちょこちょこ修正していくアプローチで、学生時代には沢山の作品(製品ではない事に注意)を作ってきました。今回の新人A君の設計は仕様を満たせるでしょうか?
新人A君は、ざざざーとプログラムを意気揚々と書き上げました。
彼の最初のバージョンは、以下のテストデータを正しく処理しました。
そして、以下のテストデータは正しく処理できませんでした。
- [CDE[FGA]]
- [[CDE]FGA]
- [[]]
- [C[D]E]
- [CD[EF]GA]
つまり、殆ど正しく処理できなかったわけです。
新人A君は「ネストなんていらないですよ。」と仕様に文句を付け始めました。
これはいけません。
中堅B君の場合
中堅B君は、現場でXX年の経験を積んだ社員です。
最近は様々な案件の検討にも加わり、かなり自信が付いています。
課題に対する設計アプローチにも幅が広がり、色々なキーワードと共にアイデアが出せる人材です。
中堅B君はスタックを使った設計アイデアの妥当性を確認するために簡単なテストプログラムを作って事前検証する事にしました。
彼の最初のバージョンは、以下のテストデータを正しく処理しました。
そして、以下のテストデータは正しく処理できませんでした。
- [CDE[FGA]]
- [[CDE]FGA]
- [[]]
- [C[D]E]
- [CD[EF]GA]
つまり、殆ど正しく処理できなかったわけです。
但し、新人A君と異なり設計にスタック構造を用いており、繰り返し開始括弧である[記号が複数やってくるところまでは、設計上でうまく対応できています。
新人A君と中堅B君
新人A君は、そもそも仕様を無視して何でも良いから動かそうとしています。
これでは何をやっているのかわかりません。
中堅B君は、スタック構造へ誘ったのは良かったのです。
が、ちょっと詰めが甘かったようです。
A tiny MML parserにおける設計
A tiny MML parserにおける設計は、以下のように行ないました。
- 簡単なスタックモジュールを設計する
- 代表的なパターンを定義する (これはテストデータの一部でもある)
- 定義したパターンを満たす一般ルールを見つける
- 一般ルールを他のパターンに適用して破綻がないか確認する
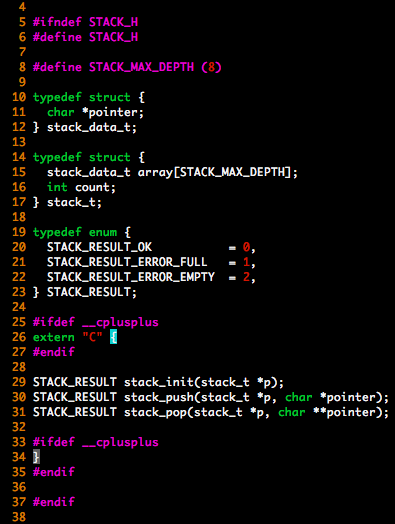
始めに簡単なスタックモジュールを設計しました。このモジュールがあまり大きいと、繰り返し処理で削減したはずのメモリを追加したスタックモジュールで食い潰す矛盾が起きてしまいます。スタックモジュールはMMLの操作とは完全に独立させ、単独で検証できるようにしました。
charへのポインタをプッシュ、ポップ出来る設計です。
このスタックモジュールの単独検証終了後、全体操作の設計を開始しました。
以下は、最初に完成した操作に関する設計メモです。
代表的なパターンを定義する事で、その次に続く一般ルールを見つける作業の前提が明らかになります。定義したパターンに対して矛盾無く処理可能な一般ルールを見つけ、それを他のパターンに適用してみます。他のパターンに適用して破綻が有る場合、それは一般ルールではなく、ある前提に依存したルールという事になります。
上記設計メモに書かれたルールは、突然箇条書きにして生まれたわけではありません。特定の代表的なパターンを用意し、二つのスタックが理想的にどのような内部状態であれば処理が出来ていると言えるのか?を考えて、それを一般ルールにしたものです。
例えば、以下のようなパターンを挙げ、Dの後ろにある終了括弧に着目します。
この終了括弧に到達した直後の理想的なスタック状態を列挙したのが以下。
後は上記のスタック状態になるような操作を一般ルールに落とし込み、その操作が派生パターンでも破綻しない事を確認します。上記の例で言うと、一番近い派生パターンから見るとして以下の3パターンでしょう。
で、LPC810には入り切った?
いいえ・・・。
予想以上にROM 4KBが厳しい制約!
どのくらい入っていないかと調べてみると、text合計が6,186[Byte]ですから約2KBほど溢れています。曲データが収められているのはmain.oで、この中に制御コードは殆ど含まれません。-Osを付けてコンパイルしたオブジェクトを、arm-none-eabi-size *.oで見た結果が以下。
今回追加したリピート処理によって、スーパーマリオの曲データは3,464[Byte]から2,175[Byte]へ約62.8%圧縮出来ましたが、その差はたったの1,289Byteでした。text合計の話と合わせると、ほぼ曲データ分だけ溢れている事がわかりました。上記を見る限り、MMLモジュールを全て取り除いたとしても入りません。そもそもMMLモジュールを取り除いては意味もありません。
あぁ、こういうアプリケーションは想定していなかったなぁという感じです。例えば、小さいプロセッサからEEPROMなどのデータを見に行くというものを考えた場合、現在のA tiny MML parserは、セットアップの時点でデータが確定している事を前提にしているので、逐次データを読みに行くような制御に対応できません。
なるほど、自分で使ってみるものだなぁと改めて思ってしまいます。
どうしようかな・・・。